요즘 딥러닝 분야에서 학계를 넘어 사회적으로 가장 널리 회자되는 모델이 GPT-3가 아닌가 싶다.
나는 NLP 분야와는 거리가 멀지만, 최신 번역 모델의 기초가 되는 transformer가 무엇인지 간단하게 알아보기로 한다
시계열 분석에 대한 아이디어를 잘캐치하면 내 분야에도 적용할 기회가 있지않을까!
학습자료로는 서울대 윤성로 교수님의 강의영상을 활용했다
코시국 동안에 촬영하신 강의를 유투브로 배포하시는 교수님들이 많이 계시는데,
대학교나 딥러닝 회사 커뮤니티에 속하지 않은 나는 매우 감사할 따름이다.
1. Attention = learned allignment (between source and target)
번역 태스크에서 단어의 배열과 어순의 변경 등을 결정하기 위해서는 배열(allignment)정보를 가지는 벡터가 필요한데, 이것이 attention의 주요 역할이다.

이전의 seq2seq 모델에서는 배열정보를 가지기 위해 encoder에서 context vector를 계산했는데, encoder가 정보를 충분히 처리할 수 없는 (overloaded 되는) 문제가 발생한다. attention 을 도입함으로써 context vector computing 을 강화해서 더 좋은 성능을 가지게 되었다.
A traditional sequence-to-sequence model has to boil the entire input down into a single vector and then expands it back out. Attention avoids this by allowing the RNN processing the input to pass along information about each word it sees, and then for the RNN generating the output to focus on words as they become relevant.
Olah & Carter, 2016
이미지캡션 분야에서도 image-to-text 를 위해 집중해야할 이미지 영역을 강조하기 위해 이용된다
2. Attenetion 의 분류
Cross attention : 입력과 출력 시퀀스 사이에 어텐션을 생성한다. (works on different sequences)
Self attention : 시퀀스 내부에서 어텐션을 생성한다 (relates different positions of a single sequence to compute its representation)
Soft attention : 모든 인풋 데이터 패치에 대해 weight를 부여하고 전체의 average를 context vector로 가진다. 모델이 smooth and differntiable 하지만 연산량이 큰 단점이 있다
Hard attenetion : 선택된 일부 데이터 패치에 대해서만 weight를 부여한다. 연산량이 적고 속도가 빠르지만 selection 은 미분불가능한 stochastic한 방법이다.
Global attention : soft attention 의 개념과 유사함. 타겟을 생성하기 위해 모든 인풋을 살펴본다
Local attention : soft 와 hard attention 이 결합된 형태. 타겟 생성에 필요한 source 위치를 예측하고 그 주변에 window를 씌워서 타겟을 생성함.
3. Transformer 모델의 기본 연산과정 ("Attention Is All You Need" 논문의 모델)
기본적으로 인코더와 디코더 레이어를 쌓아서 many-to-many 맵핑을 수행하는 seq2seq 모델의 일종이다.
Encoder: 구조적으로 동일하고 가중치를 공유하지않는 6개의 레이어로 구성된다. 각각 2개의 sub-layer로 구성되어있는데 첫번째는 self-attention , 두번째는 feed-forward-net 이다.
Decoder: 3개의 sub-layer로 구성되어있다. 첫번째는 self-attetion, 두번째는 encoder-decoder attention, 세번째는 feed-forward-net
트랜스포머 논문에서는 key와 value의 개념을 이용해서 다음과 같이 정의된 표현을 사용한다
Query: (projected) decoder hidden state
Key: (projected) encoder hidden state for attention weight computation
Value: (projected) encoder hidden state for context vector build
Context Vector = weighted sum of values
(위치의 weight 또는 score 값은 query 와 key를 내적해서 생성됨)
모델의 연산 과정
(그림은 https://jalammar.github.io/illustrated-transformer/ 에서 가져옴)
(1) Query, Key, Value 를 생성
encoder에서 단어를 벡터로 word-embedding (1X512 벡터) 하고,
행렬 W_q, W_k, W_v 를 곱해서

(2) 각 단어의 self-attention socre를 생성한다
위에서 정의한대로 score = query 와 key 를 내적한 값이다.
그 결과, 입력 시퀀스의 여러 단어(=key)에 대한 attention score 값이 생성된다

(3) attention score 를 normalize 한다
key 벡터의 길이가 64이므로, 제곱근인 8로 나누어주는 scaled-dot-product 를 적용한다. 정규화 를 통해 more stable gradient 를 얻는 장점이 있다
그리고 softmax를 적용해서 score를 probability 값으로 변환해준다

(4) self-attention layer의 output 를 계산한다
여기서 attention layer의 output (=context vector) 는 weighted sum of value vectors 이다.
즉 앞서 구한 softmax 값을 이용해서 z1 = v1*0.88 + v2*0.12 으로 계산된다

위의 과정을 행렬로 나타내면 다음과 같이 간단하게 표현할 수 있다

(5) multi-head attention
트랜스포머 모델은 각각 다른 방식으로 attention을 계산하기 위해서 8개의 attention head를 가진다.
그리고 multi-heads (z0, z1, ,,, z7) 를 하나로 concat한다.

(6) Positonal-Encoding
각 단어가 문장에서 어디에 위치하는지 정보를 표현하는 벡터이다. 단어의 문장 내 위치와 다른 단어들과의 거리를 나타낼 수 있다. 본 논문에서는 20개 position에 대해 sin 함수를 이용해서 -1과 1사이의 값을 더한다 (물론 word-embedding 되었으므로 각 위치는 512개 차원의 값을 가진다)

(7) Add and Norm 서브레이어
Encoder에는 레이어를 스킵하는 residual connection 를 추가한다. 그림에서는 즉 x를 z에 더해주는 skip connection 이다. 그리고 그 결과를 layer normalization 를 수행한다.
즉 모든 Encoder 에서 Add and Norm 이라는 sub-layer 계산이 2번씩 추가되는 것으로 볼 수 있다.

(8) Decoder 레이어의 특징
인코더와 달리 encoder-decoder attention (=cross attention) 레이어를 가진다. 이 attention은 디코더가 인풋 시퀀스의 각 부분에 가중치를 가질 수 있도록 한다.
self-attention 계산과정에서 아직 생성되지않은 뒷 부분에 대한 attention을 가지지 않도록 수정된 구조(masked self-attention)를 가진다.
(9) 최종 결과물 생성하는 Logits and Softmax Layer
디코더의 최종 값은 float vector 꼴로 생성된다. 이를 단어로 변환하기 위해서 vocab size 수준의 매우 큰 Logits 로 바꿔야한다. 그리고 Logit vector 를 softmax 확률로 계산해서 가장 적합한 단어를 판정한다.
결과를 생성하는 방법으로는
① greedy decoding : softmax 확률이 가장 높은 단어를 추출한다
② beam search : beam size (=k) 개의 단어 후보를 동시에 고려하되, top beams(=t) 만큼의 결과만 저장해서 greedy 하게 진행한다.

자 이제 "Attention Is All You Need" 논문에 나온 아래 트랜스포머 모델의 모든 요소를 다 이해했다!
교수님 감사합니다 !!

이후 강의에서 BERT와 GPT 모델에 대해서 설명해주시는데
번역 모델들에 대해 너무 자세히 알아볼 필요는 없으므로 트랜스포머 정리는 여기까지 !
### 추가로 참고하면 좋은 자료
ICML2019 tutorial : Attention in Deep Learning
'데이터 사이언스 or 엔지니어링 > 머신러닝' 카테고리의 다른 글
| 모델의 Loss Surface (0) | 2022.02.23 |
|---|---|
| mini-batch 를 사용하는 이유 (0) | 2022.02.22 |
| Softmax 알아보기 (0) | 2022.02.20 |
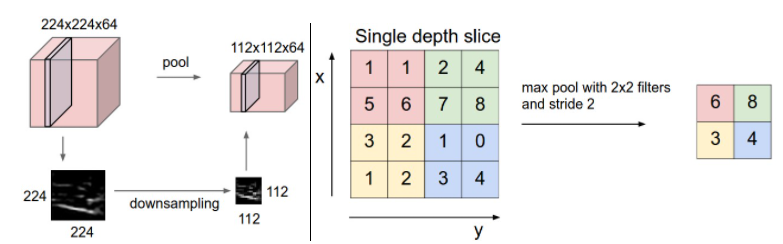
| 이미지 처리에서 CNN과 max pooling (0) | 2022.02.09 |
| ReLU를 사용하는 이유 (0) | 2022.02.03 |