남세동 대표의 딥러닝 질문리스트 중 마지막으로 다뤄볼 내용은 optimizer의 momentum과 ADAM 알고리즘이다
(그 외 내용은 다른방식으로 다루었거나 다룰 예정)
Adam은 입문단계에서 묻지도따지지도말고 국룰이라 momentum과 Adam은 많이들 익숙한 내용일 것이다
Adam 논문은 2022년 현재 피인용수 10만 무렵이지만,
너무 trivial 하여 인용하지않았거나 논문으로 발간되지 않은 사용사례가 그 몇배는 될 것으로 예상한다
Andrew Ng 님의 강의 Gradient Descent With Momentum (C2W2L06) 를 기초로
수식과 함께 정확하게 정리해보자
6. Optimizer에서 momentum은 무엇인가요?
a. momentum을 수식으로 적어본다면 어떻게 되나요?
기본적인 gradient descent 에서는 optimizer(최적화 알고리즘) 에 의해 모델의 오차가 줄어들도록 설정한다
이 때, learning rate가 작으면 학습이 너무 오래걸리거나 local minima에 빠질 수 있고,
learning rate가 크면 학습이 overshooting 또는 diverge 되는 문제를 야기할 수 있다.
이를 극복하기 위해서 momentum은 gradient가 일관적인 방향으로 조금 더 빠른 최적화를 수행하도록하는 term이다
momentum의 수식을 이해하기 위해 먼저 Exponentially Weighted Moving Average (지수가중이동평균)의 개념을 짚고 넘어가자
데이터의 이동평균을 구하기 위해 현재 평균값과 새로 추가되는 데이터를 β만큼 가중치를 준다면
V(t) = β*V(t-1) + (1- β)*θ(t) 로 표현할 수 있다.
다시말하면 β 값이 클수록 직전의 평균값에 더 큰 가중치를 주는 것이다.
이 때 V(t)≈ avg. of 1/(1-β) days 라는 성질을 가진다. 예를 들어 β=0.9라면 V(t)는 10일치의 평균과 유사하다.
더 긴 기간의 이동평균을 계산하므로 더 smooth 한 V(t) 그래프를 얻을 수 있다.
momentum 의 정의는 gradient의 지수가중이동평균을 구하는 것이다
위에서 적은 수식과 마찬가지로 weight 또는 bias 의 gradient 를
V(dw) = β*V(dw) + (1-β)*dw 로 정의하고
learning rate α를 적용해서 W=W-αV(dw) 로 모델을 업데이트할 수 있다.

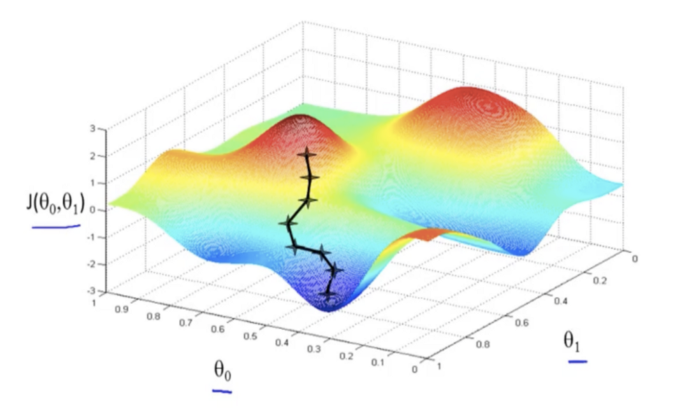
예를 들어 cost function이 아래 그림과 같다면
수직방향으로의 이동폭은 줄이는 동시에, 수평방향(오른쪽)으로의 이동폭을 늘여야 빠르고 정확하게 모델이 최적화된다.
momentum은 gradient의 이동평균을 이용해서 "이전에 가던 방향"으로의 학습을 빠르게 만들어 준다.

learning rate 와 momentum의 설정에 의한 모델 최적화 결과를 시각화하면 보다 직관적인 이해가 가능하다
( https://distill.pub/2017/momentum/ )
momentum을 이용하면 모델이 global minima와 거리가 먼 초기 단계에서는 학습속도를 빠르게 진행시키고
학습이 진행될수록 momentum이 작아지면서 정밀한 fine tuning이 가능해진다.

b. Adam은 어떻게 동작하나요?
Adam은 momentum 방식과, RMSProp(Tieleman & Hinton, 2012)을 결합한 최적화 알고리즘이다.
참고로 RMSProp는 제곱항과 제곱근을 이용해서 아래와 같이 계산하는 방식이다.
기본적인 원리는 모멘텀과 크게 다르지않다.

Adam논문에서 쓰인 알고리즘을 바로 보자

여기서 β1로 계산한 m_t 가 momentum 파라미터이고,
β2 와 제곱항으로 계산한 v_t가 RMSProp 에서 차용한 파라미터이다.
bias correction 은 크게 신경쓰지않아도 되고..
모델 업데이트 과정에서 momentum과 RMSProp의 업데이트 방식을 결합한 것을 볼 수 있따.
Adam은 이처럼 기존의 아이디어들을 개선한 결과물이지만
굉장히 좋은 성능으로 딥러닝 입문단계나 모델 개발과정에서 고민을 줄여주는 고마운 알고리즘이다
'데이터 사이언스 or 엔지니어링 > 머신러닝' 카테고리의 다른 글
| XGBoost - 원리와 수식까지 이해해보기 (0) | 2022.03.17 |
|---|---|
| 결정트리 알고리즘 - bagging 과 boosting (0) | 2022.03.15 |
| 모델의 Loss Surface (0) | 2022.02.23 |
| mini-batch 를 사용하는 이유 (0) | 2022.02.22 |
| Transformer 의 기초 이해하기 (0) | 2022.02.21 |